
STUDIU. Au fost descoperite aproape 100 de gene noi asociate cu un risc înalt de apariție a cancerului mamar. O nouă era în prevenția și terapia personalizată a bolii?
Cel mai amplu studiu de până acum care a analizat bazele genetice ale cancerului de sân a fost realizat de o echipă de cercetători de la Institute of Cancer Research (ICR) din Londra și publicat în Nature Communications. 110 gene asociate cu un risc înalt de apariție a cancerului de sân, dintre care 32 corelate cu rata de supraviețuire, au fost analizate printr-o tehnică modernă de secvențiere genetică. Majoritatea acestor gene sunt NOI, ceea ce înseamnă că sunt posibile ținte terapeutice.
Astfel s-a reușit nu doar identificarea unor noi gene implicate, ci și elucidarea rolului unor interacțiuni fizice între componente ale ADN-ului aflate chiar la distanțe de milioane de nucleotide. Studiul poate înseamna începutul unui nivel superior în tratamentul personalizat al cancerului de sân – noi teste genetice care pot prezice riscul de cancer precum și noi tipuri de terapii țintite.

„Am studiat modul în care ADN-ul formează anumite bucle ce permit interacțiunea dintre gene la risc și porțiuni din ADN dintr-o zonă total diferită a genomului. Identificarea acestor gene ne poate ajuta să prezicem riscul unei femei de a dezvolta cancer de sân cu mai multă acuratețe, dar și vor contribui la apariția de noi tratamente țintite” – Dr. Olivia Fletcher, investigator ICR.
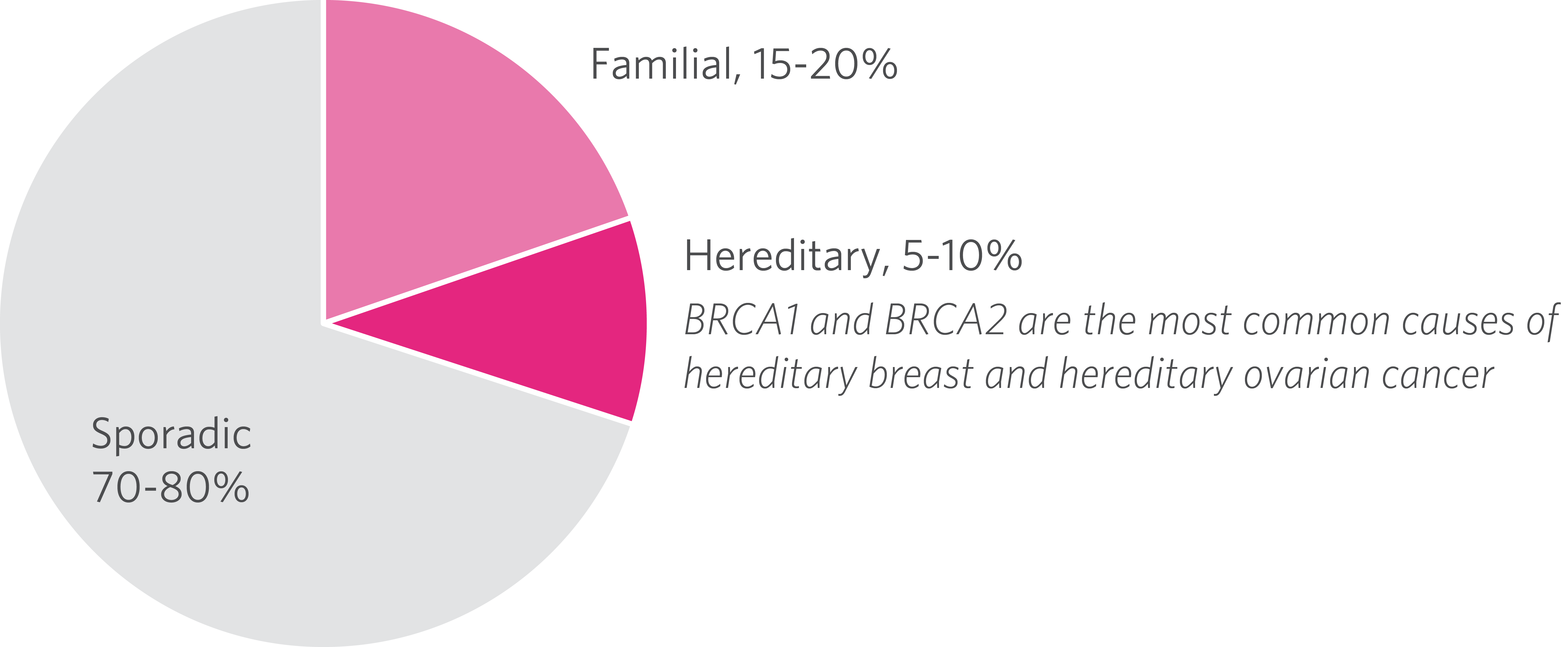
De la descoperirea genei BRCA1, în 1994 și a genei BRCA2 un an mai târziu, s-a deschis calea tratamentului personalizat al acestui tip de cancer. Între 5 și 10% dintre cancerele de sân la femeie sunt considerate ereditare, iar dintre acestea cele mai multe sunt atribuite mutațiilor BRCA1 și 2. Mutațiile BRCA reprezintă 90% din cazurile de cancer de sân care au o influență genetică. Riscul de dezvoltare a cancerului apare la 60-80% dintre cei afectați.
Studiul realizat de ICR marchează un nou nivel de înțelegere a geneticii cancerului mamar, cu implicații ce ar putea fi salvatoare de vieți.
Identificarea genelor modificate care cresc riscul de cancer de sân nu este suficientă, deoarece anumite secvente din ADN „la risc” pot interacționa cu alte părți din genom în cadrul unui fenomen numit „looping ADN”. Elementul de noutate în cadrul aceestui studiu este legat de tehnica Capture HiC – o metodă ce permite analizarea interacțiunilor dintre zone diferite ale genomului. Prin studiu nu s-au identificat doar genele responsabile de un risc mai mare de apariție a cancerului ci și modul în care acestea determină acest risc.
63 de porțiuni genomice, care până acum erau considerate implicate în apariția cancerului de sân, au fost analizate, realizându-se adevărate hărți ale ADN-ului.
Capture Hi-C este o tehnică de înaltă rezoluție care poate identifica modul în care elemente reglatoare de la nivelul genomului (gene care nu codifică proteine) interacționează cu secvențe genetice care codifică proteine deși se află la distanțe de ordinul megabazelor de ADN. Cercetătorii de la ICR au folosit metoda pentru a analiza 63 de regiuni genomice care prin studii anterioare – mai exact studii de asociere la nivelul întregului genom (GWAS- genome-wide-association studies), s-au dovedit a se corela cu riscul crescut de apariție a cancerului mamar.
Echipa a evaluat rezultatele comparându-le cu trei baze de date referitoare la cancerul de sân, pentru a determina dacă există o relație cauzală între genele identificate și riscul de neoplasm. Au descoperit că 32 dintre cele 97 de gene pentru care existau date disponibile s-au asociat cu rata de supraviețuire în cancerele ER+.
Autorii studiului afirmă că datele obținute sugerează că o mare parte dintre genele descoperite de ei au o influență semnificativă pentru riscul de cancer la sân, ceea ce garantează nevoia de investigații amănunțite pe acest subiect. De asemenea, aceștia declară că ar putea dura ani întregi până se va putea afirma cu certitudine ce gene joacă un rol categoric în riscul de apariție a cancerului mamar, însă prima fază este aceea „de a reduce lista candidaților pentru studii de follow-up”.
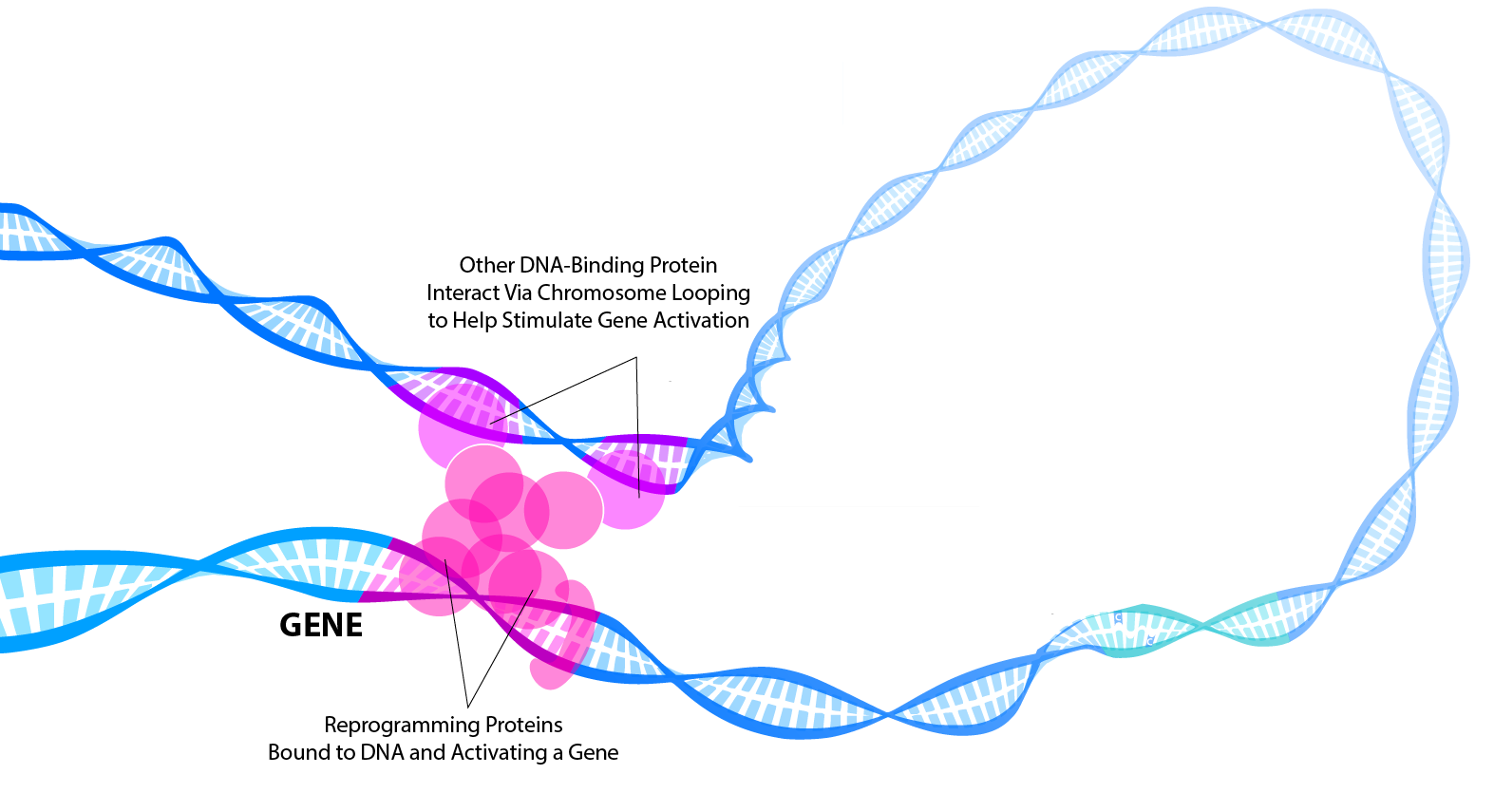
În 33 de regiuni s-au identificat gene specifice care influențează modificările care declanșează cancerul mamar și ar putea reprezenta ținte terapeutice noi – 94 de gene care codifică proteine și 16 regiuni necodante, cu rol reglator. În restul de 30 de regiuni nu s-au identificat gene specifice.
Studii genetice mai vechi identificaseră doar 14 dintre cele 110 gene care ar fi responsabile de creșterea riscului de cancer mamar în populație – gena receptorului de estrogen, ESR1, de exemplu.
S-a identificat însă și gena FADD, care până acum a fost implicată în cancerul de cap și gât precum și în cancerul pulmonar, și care ar putea reprezenta o nouă țintă pentru tratament și în acest caz.
Descoperirea permite ca identificarea femeilor care au cel mai mare risc de a dezvolta boala să se realizeze mult mai ușor, iar implicațiile terapeutice ar putea fi semnificative, astfel fiind găsite alte ținte pentru terapia personalizată a cancerului mamar. Cele mai multe dintre cele 110 gene nu au fost asociate cancerului de sân până acum și se pare că interacțiunile de tip „looping” joacă un rol important în acest tip de neoplasm.
„Studii de genomică pe scară largă au corelat zone din ADN cu riscul de apariție a cancerului mamar. Acest studiu se concentrează pe aceste regiuni în detaliu, descoperind „o comoară” de gene, care pot fi analizate în prezent cu mult mai multă acuratețe. Modurile în care anumite gene influențează riscul de cancer sunt complexe. O înțelegere mai bună a genelor pe care le-am identificat în acest studiu ar putea conduce la descoperirea de noi terapii individualizate sau de noi strategii de îmbunătățire a procesului de diagnosticare și prevenție a bolii” – Dr. Paul Workman, director ICR.
Articole similare
- #ASCO2017: Olaparib încetinește progresia cancerului la sân metastatic, BRCA-pozitiv
- Dr. Mark Robson: olaparib vs. chimioterapie standard în tratarea cancerului la sân BRCA-pozitiv
- #ESMO17. 75% dintre pacientele cu cancer mamar sau ovarian nu și-au făcut testarea genetică, deși ar fi trebuit